Dataset management
We should split our dataset into 3 parts:
- train set - used to train our algorithm
- validation - used to tune hyper parameters
- test set - used to check accuracy on unseen data
Splitting the dataset into 80% training data and 20% test data.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
K-fold validation
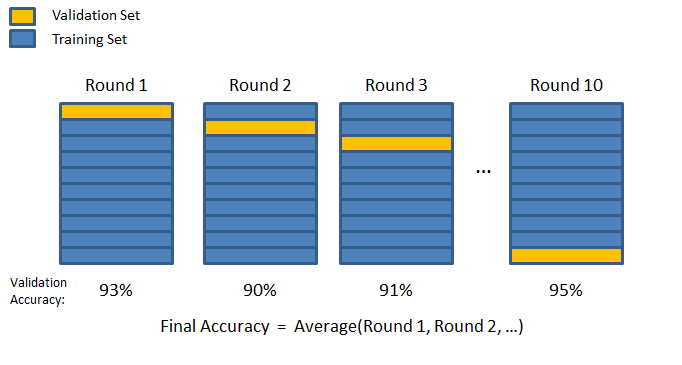
In K-fold validation we split the dataset into K equally sized chunks. We select the one as the validation chunk, and the rest as training chunks; we train and measure accuracy. Repeat this until all chunks have been used as validation chunks.
Pipeline
When we develop complex machine learning systems we should split our problem into smaller chunks, to have a way of better allocating our resources. For this we can use pipelining. Resources on this page come from AndrewNG’s ML course1.
For instance, for a photo OCR algorithm this is what the pipeline might look like.

Ceiling analysis

Measure the overall accuracy (or other metric) of the system. Then take the first stage of the pipeline, and replace if with one with 100% accuracy (manually selected pictures for ex.). Measure accuracy again. Do so for all of the stages and write down the results in a table.
Increasing your dataset size
First you should make sure you have a low bias classifier. If not you can increase the number of features/hidden layers to lower the bias.
Ask yourself: how much work would it take to get 10x as much data as I have now?
- Artificial data synthetics
- Manual labelling
- Crowd source (Amazon mechanical turk)
Synthetizing data
You can introduce distortions to images, background noise to sound samples etc. Usually adding random noise does not help.
Your distortions should be consistent to the kind of distortions you expect to see in the test set.